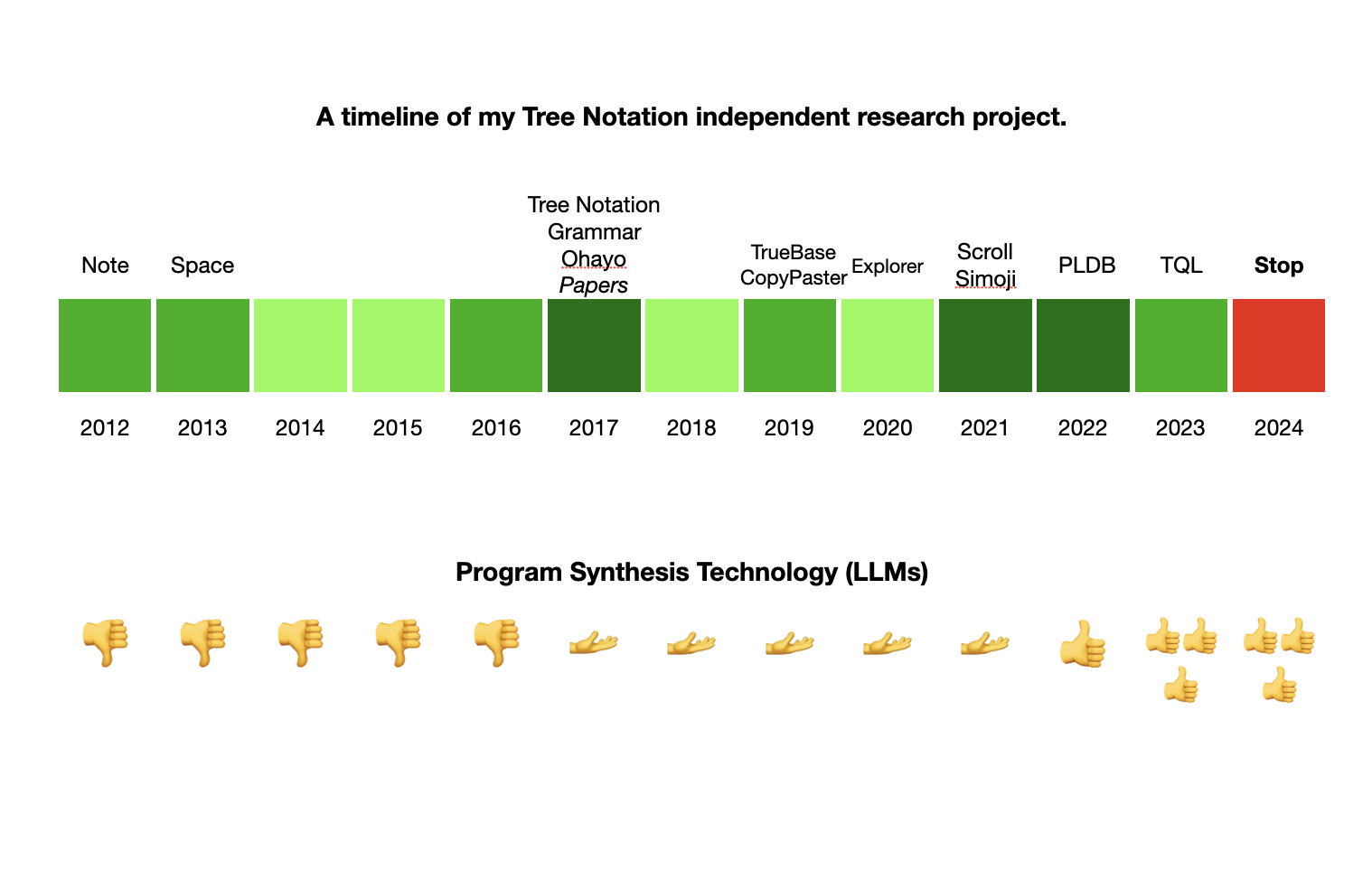
April 2, 2024 — It has been over 3 years since I published the 2019 Tree Notation "Annual" Report. An update is long overdue. This is the second and last report as I am officially concluding the Tree Notation project.
I am deeply grateful to everyone who explored this idea with me. I believe it was worth exploring. Sometimes you think you may have discovered a new continent but it turns out to be just a small, mildly interesting island.
Hypothesis
Tree Notation was my failed decade long research project to find the simplest universal syntax for computational languages with the hypothesis that doing so would enable major efficiency gains in program synthesis[1] and cross domain collaboration. I had recognized all computational languages have a tree form, a 2D grid gave you enough syntax to encode trees, and maybe different syntaxes of our languages was holding us back from building the next generation of programming tools.
Results
The breakthrough gains of LLMs in the past eighteen months have clearly demonstrated that I was wrong. LLMs have shown AIs can read, write, and comprehend all languages across all domains at elite levels. A universal syntax was not what we needed for the next generation of symbolic tools, but instead what we needed was attention layers, smarter chips, huge training efforts, et cetera. The difference between the time of the last report and now is that the upside potential of Tree Notation is no longer there. Back in 2019, program synthesis was still bad. No one had solved it. Tree Notation was my attempt to solve it from a different angle.
Reflection
The failure of this project will come as no surprise to almost everyone. Heck, in the 2019 report even I say "I am between 90-99% confident that Tree Notation is not a good idea". However, we kept making interesting progress, and though it was a long shot, if it did help unlock program synthesis that would have had huge upside. I felt compelled to keep exploring it seriously.
Back in 2019 I wrote "No one has convinced me that this is a dead-end idea and I haven't seen enough evidence that this is a good idea". I have now thoroughly convinced myself, in large part to the abundant evidence provided by LLMs[2], that Tree Notation is a dead-end idea (I would call it mildly interesting, it's still mildly useful in a few places).
Maintenance
I am not ending work 100%. More like 98%-99%. I will likely always blog and am writing this post in Scroll, an alternative to Markdown built on Tree Notation, which I personally enjoy and will continue to maintain. Someday AI writing environments may become so amazing that I abandon Scroll for those, but until then I expect to keep maintaining Scroll and its dependencies. I will also continue to add to PLDB, but have little time to uplevel it and am open to handing it off.
Financial Losses
I feel good about this effort from society's perspective as the world got a mildly interesting idea explored and the losses were privatized. I effectively lost all my money pursuing this line of research, at least in the hundreds of thousands in direct costs of failed applications and more in lost salary opportunity costs. But also, this effort did lead me on a path with certain lucrative side gigs and maybe I would have had less to lose had I not taken it on. Who knows, maybe the new 4D language research (see below) will lead to future gains.
Status of Long Bet
After someone suggested it, in 2017 I made a Long Bet about Tree Notation. My confidence came from my hunch that Tree Languages would be far easier for program synthesis, which would lead to more investment into Tree Languages, which would have network and compounding effects. Instead LLMs solved the program synthesis problem without requiring new languages, eliminating the only chance Tree Languages had to win. So, I now forecast a 99.999% chance the first part of that bet will not win.
My bet did have two clauses, the second predicting "someone somewhere may invent something even better than Tree Languages...which blows Tree Notation out of the water."[3] This has sort of happened with LLMs. At the time of the bet I felt we were on the cusp of a program synthesis breakthrough that would radically change programming, and that happened, it just happened because of a new kind of (AI) programmer and not a new kind of language.
The bet was not about a general breakthrough in programming, but specifically about whether there will be a shuffling in our top named languages. So I see 99.X% odds I will lose the second clause of the bet as well. There remains a chance LLMs make another giant leap and who knows, maybe we start considering something like Prompting Dialects a language ("I am a programmer who knows the languages Claude and ChatGPT"). But I don't see that as likely, even if we are still on the steep part of the innovation curve.
The Other Reason I liked Tree Notation
LLMs have eliminated the primary pragmatic reason for working on Tree Notation research--they solved the program synthesis and cross domain collaboration problems. But I also enjoyed working on Tree Notation because it gave me an attack vector to try and crack knowledge in general. Now, however, I see a far better way to work on that latter problem.
Future Explorations: 4D languages
Looking back, I recognize I had a strong bias for words over weights. The mental resources I used to spend exploring Tree Notation I now use to explore 4D languages (with lots of 1D binary vectors for computation). Words are merely a tool for communicating thoughts. Thoughts compile to words and words decompile back to thoughts. I am now exploring the low level language of thought itself. Intelligence without words. The 4D language approach seems to be an orders of magnitude more direct route than Tree Notation to finding the answers I am looking for. I feel silly for taking so long to see a truth that an average ancient Greek citizen would probably know. But to err is human, I hear.
Conclusion
I called the first status update an "Annual Report", which was optimistic thinking. It took me years to get another one out. And it turns out this will be the last one.
It would have been great personally to have been right on this long shot bet, but in the end I was wrong. I absolutely gave it everything I had. I poured much blood, sweat, and tears into this effort. I was stubborn and persistent to figure out whether this had potential or was just mildly interesting. I had a lot of help and support and am deeply grateful. I am sorry the offshoot products were not more useful (or good looking).
It took me a while to let Tree Notation go. Even after LLMs destroyed the potential upside of pragmatic utility of the notation, I still liked it because it gave me an interesting way to work on problems of knowledge itself. It wasn't until I had some insights into 4D languages that I finally could say there was no longer any need for Tree Notation. I am grateful for the experience and have now moved on to a new research journey.
[1] Program synthesis: the ability for a computer to generate the right code. Just a unique term for the concept of really good autocomplete.
[2] And in particular, understanding the model that explains why LLMs succeeded while my approach failed.
[3] The ellipsis here removes from the bet the words "perhaps a higher dimensional type of structure". Who knows? ;)